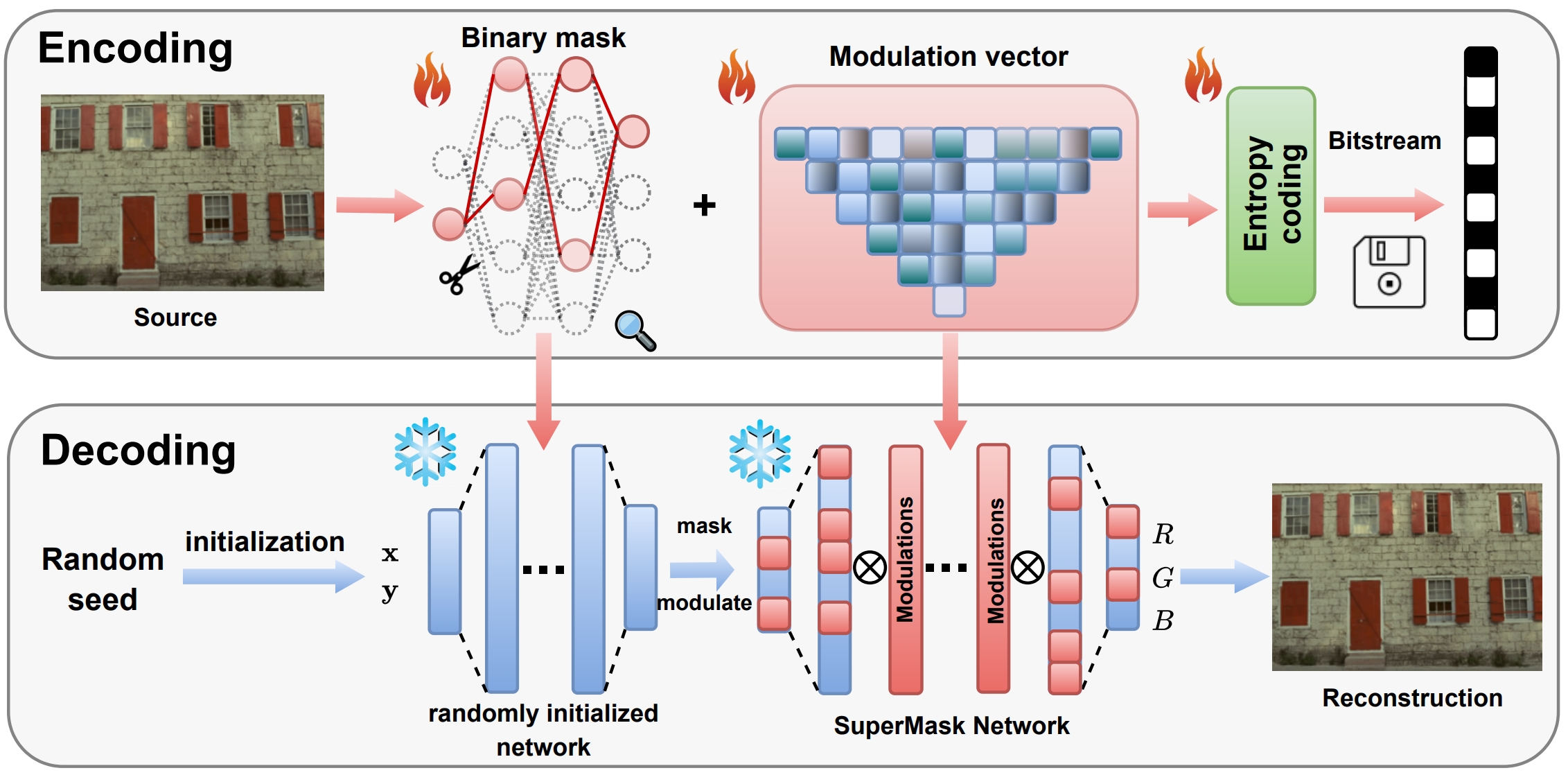
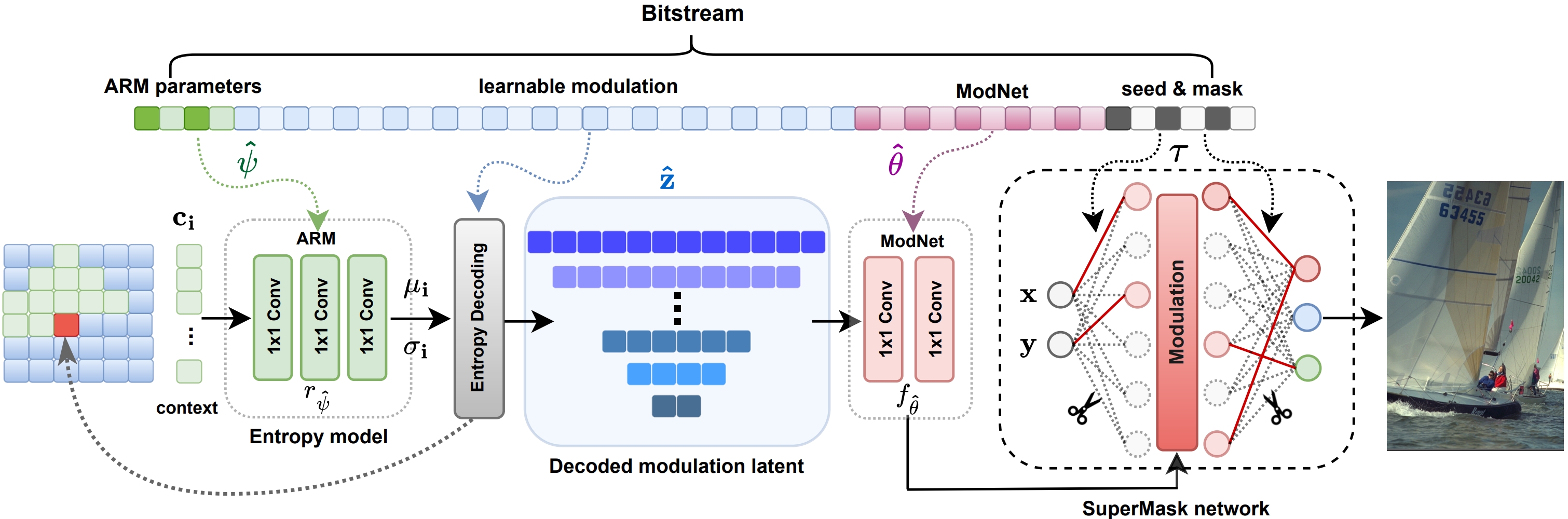
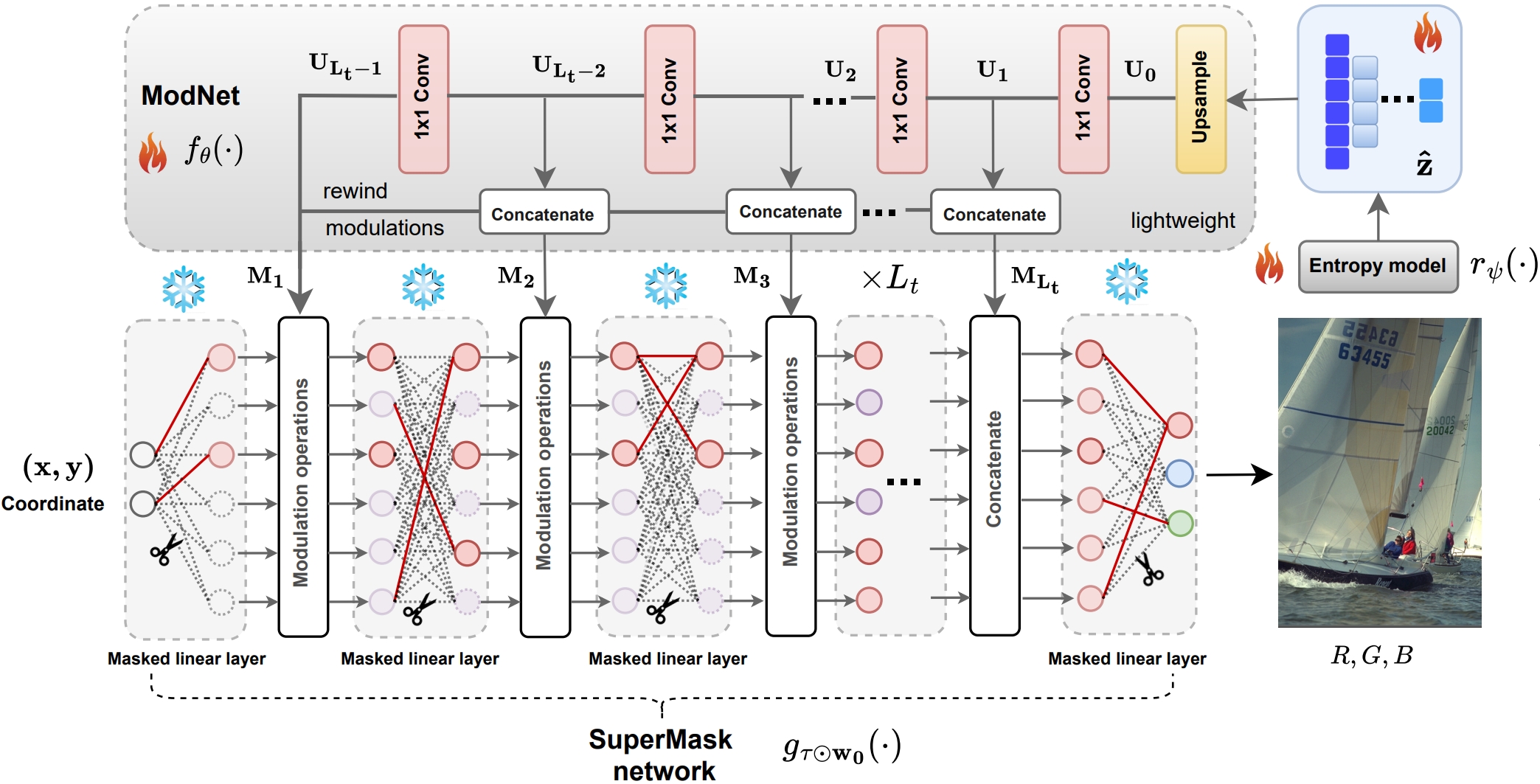
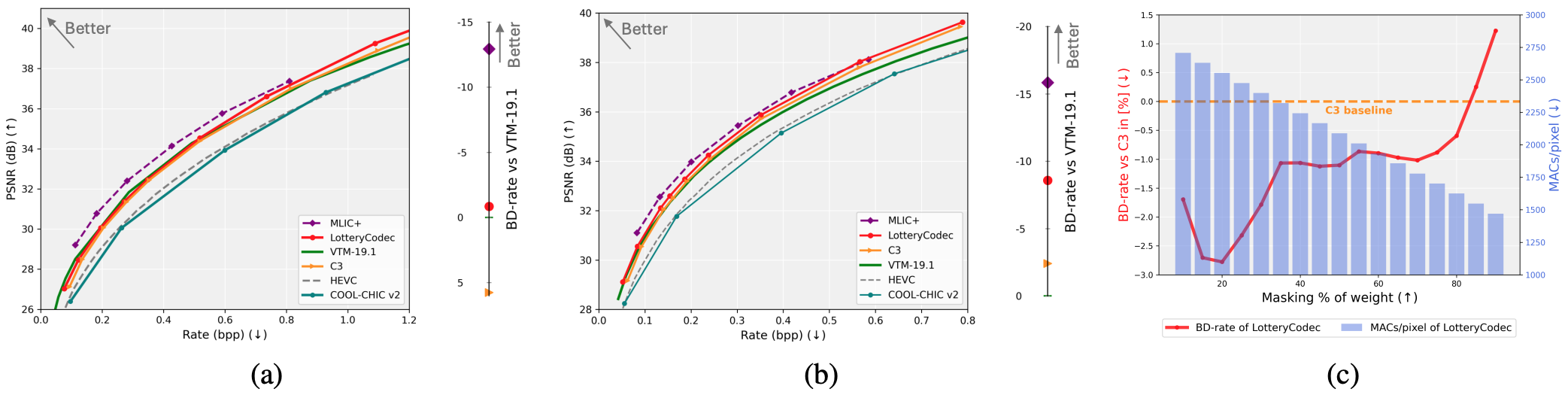
We study zero-shot inverse problems, where a clean signal is recovered from a single degraded observation without external training data. Contrary to the common belief that such problems require highly complex models, we show that a lightweight neural network, when combined with entropy and complexity regularization in a compression-based formulation, is sufficient for high-quality restoration. We propose Lottery Prior, a compression-based inverse solver that leverages architectural priors from random networks and induces a family of implicit priors through randomness, enabling ensemble-based refinement. We further derive non-asymptotic error bounds for compression-based maximum-likelihood inverse solvers, revealing how rate–distortion constraints act as implicit regularizers. Experiments on denoising, noisy super-resolution, and inpainting demonstrate that our method achieves state-of-the-art with significantly fewer effective parameters.